Prawa i przepisy regulujące bezpieczeństwo cybernetyczne
8. Prywatność i bezpieczeństwo w ICT, ochrona danych w cyberprzestrzeni
8.1. Ślad cyfrowy
Zagrożenia te, a raczej ryzyka, bardzo często dotyczą pozostawiania śladów cyfrowych w cyberprzestrzeni. Ślady cyfrowe, w zależności od tego, czy użytkownik może na nie wpływać, czy nie, można ogólnie podzielić na ślady, na które można wpływać, i ślady, na które nie można wpływać.
Dzielenie ścieżek cyfrowych:
· Ślad cyfrowy pozostaje nienaruszony
- informacje z systemu komputerowego;
- połączenie z sieciami komputerowymi, zwłaszcza z Internetem;
- wykorzystanie świadczonych usług itp.
· Cyfrowy ślad ma wpływ na
- świadome korzystanie z usług;
- dobrowolne ujawnianie informacji
· blogi, fora
· sieci społecznościowe,
· e-mail,
· magazyny danych,
· usługi w chmurze itp.
W dalszej części artykułu omówię niektóre aspekty poszczególnych śladów cyfrowych i zawartych w nich informacji. Celem jest zwrócenie uwagi użytkownika na to, że jego działania w środowisku TIK nie są tak anonimowe, jak mogłoby się wydawać.
W świecie technologii informacyjno-komunikacyjnych obowiązuje jedna zasada: gdy cokolwiek przesyłasz, transmitujesz, pośredniczysz, umieszczasz w cyberprzestrzeni, pozostaje tam "na zawsze". Zawsze będzie istniała kopia (utworzona dzięki funkcjonalności systemu komputerowego lub przechowywana przez innego użytkownika) danych użytkownika. Nawet jeśli użytkownik usunie te dane, nie dojdzie do ich faktycznego, trwałego i nieodwracalnego usunięcia. Dlatego warto zwracać uwagę na swój cyfrowy ślad oraz informacje i dane, które pozostawiamy w cyberprzestrzeni.
8.1.1 Ślad cyfrowy pozostaje nienaruszony
Ślady nieinfluencyjne są najczęściej tworzone przez interakcję jednego systemu komputerowego z innym systemem komputerowym lub przez funkcjonalność systemu komputerowego (i związanego z nim oprogramowania). Przykłady takich śladów obejmują informacje z systemu operacyjnego (np. komunikaty o błędach systemu Windows lub informacje systemowe) lub inne informacje i dane, które są przechowywane w oparciu o funkcjonalność systemu bez konieczności ich przesyłania (np. system komputerowy nigdy nie był podłączony do żadnej sieci lub innego systemu komputerowego).[1] Nie do końca słuszne byłoby bezkompromisowe stwierdzenie, że na te ślady nie można wpływać. Jeżeli użytkownik posiada wystarczające umiejętności, może zmodyfikować, zamaskować lub zlikwidować wiele "nieinfiltrowanych" śladów cyfrowych (np. po prostu używając trybu anonimowego w przeglądarce internetowej w celu wyłączenia plików cookie). Jednak ruch użytkownika w Internecie może być śledzony na różne sposoby.
Adres IP
Podłączenie systemu komputerowego do Internetu jest typowym przykładem stosunkowo nieuciążliwego śladu. Adres IP lub adres MAC, który jest przekazywany wraz z innymi informacjami do dostawcy usług internetowych. Adres IP nie jest domyślnie anonimowy i jest używany przez system komputerowy jako jeden z jego identyfikatorów podczas komunikacji z innymi systemami komputerowymi. Adresy IP są przydzielane hierarchicznie, przy czym dominującą rolę odgrywa ICANN, która podzieliła świat rzeczywisty na regiony zarządzane przez Regionalne Rejestry Internetowe (RIR). Rejestratorzy ci otrzymali od ICANN zakres adresów IP, które przydzielają adresom LIR w swoim regionie. Rejestratorzy regionalni są podzieleni na pięć następujących jednostek terytorialnych
1. Obszar "euroazjatycki" - RIPE NCC: https://www.ripe.net/
2. Region "Azja i Pacyfik" - APNIC: https://www.apnic.net/
3. Region "Ameryka Północna" - ARIN: https://www.arin.net/
4. Region "Ameryka Południowa" - LACNIC: http://www.lacnic.net/
5. Region "afrykański" - AFRINIC: http://www.afrinic.net/

Rysunek - Światowy podział między RIR
Regionalni rejestratorzy witryny[2] prowadzą na swoich stronach internetowych usługę Whois, która jest nazwą bazy danych zawierającej informacje o posiadaczach adresów IP. Te bazy danych zawierają szereg informacji, które można wykorzystać do zidentyfikowania np. zakresu używanych publicznych adresów IP, danych kontaktowych, kontaktu w sprawie nadużyć[3] , hierarchicznego macierzystego dostawcy usług internetowych itp. Często możliwe jest wykorzystanie tych ogólnodostępnych baz danych w celu zidentyfikowania "właściciela" (operatora, dostawcy) danego adresu IP. [4]
Rejestratorzy regionalni następnie rozdzielają przydzielone zakresy IP między lokalnych rejestratorów internetowych (LIR). Lokalnym rejestratorem jest zazwyczaj dostawca usług internetowych (w Republice Czeskiej jest to dostawca usług społeczeństwa informacyjnego, a konkretnie dostawca łącza, publiczny lub niepubliczny). Rejestrator ten może następnie udostępnić swój zakres adresów IP na przykład części swojej organizacji lub innym podmiotom.

|
Rysunek - Wyodrębnianie informacji z bazy danych RIR |
Dzięki ścisłym zasadom określającym zarządzanie adresami IP oraz publicznie dostępnym bazom danych RIR zawierającym informacje o posiadaczach poszczególnych bloków adresowych można szybko ustalić, do jakiej sieci należy dany adres IP i kto jest jego operatorem. Operator danej sieci może ustalić, kto (lub jaki system komputerowy) korzystał z danego adresu IP w określonym czasie, rejestrując informacje o ruchu sieciowym. Identyfikacja ta stanowi bardzo ważne źródło informacji podczas postępowania z incydentami bezpieczeństwa (cyberatakami) oraz podczas poszukiwania ich źródła (inicjatora).
Poczta elektroniczna jako jedna z najczęściej używanych usług w środowisku internetowym, z pewnością nie jest usługą anonimową. Wiadomość wysyłana ze źródła do miejsca docelowego (odbiorcy) zazwyczaj zawiera różne informacje, które pozwalają zidentyfikować zarówno dostawcę usługi (poczty elektronicznej), jak i dostawcę połączenia z urządzeniem, z którego wysłano wiadomość. Informacje te nie są wyświetlane w treści wiadomości (tj. w tekście wysyłanym do konkretnej osoby), lecz w kodzie źródłowym (nagłówku) wiadomości. Z tego kodu źródłowego można dowiedzieć się na przykład o ścieżce przez serwery, faktycznym nadawcy, nazwie komputera źródłowego, nazwie komputera, czasie wysłania wiadomości (wraz ze strefą czasową), używanym systemie operacyjnym, kliencie poczty itp. Poniżej znajduje się przykład nagłówka przesłanej dalej wiadomości[5] z potencjalnie interesującymi informacjami, które zostały wyróżnione.

Obraz - wyświetlanie informacji z nagłówka wiadomości e-mail
Przeglądarka internetowa
Przeglądarka internetowa to kolejna aplikacja, która domyślnie przekazuje informacje o użytkowniku i jego systemie komputerowym do systemu komputerowego (serwera) odwiedzanej witryny. Serwer ten następnie, w ramach zapytania od klienta, ustala np. referrer (czyli stronę, z której przyszedł użytkownik), używaną przeglądarkę internetową i system operacyjny (w tym dokładną wersję), pliki cookie, pliki flash cookie, historię, pamięć podręczną itp.
Oprócz adresu IP, to właśnie między innymi pliki cookie[6] pomagają stworzyć "odcisk palca" systemu komputerowego użytkownika (komputera, smartfona itp.). Ten odcisk palca umożliwia identyfikację konkretnego systemu komputerowego[7] , nawet jeśli użytkownik korzysta z innej przeglądarki internetowej, usuwa pliki cookie, loguje się z innego adresu IP itp.
Jedną z wielu obecnie stosowanych metod "fingerprintingu" jest canvas fingerprinting.[8] Canvas fingerprinting działa poprzez instruowanie przeglądarki internetowej użytkownika, aby "narysowała ukryty obraz", gdy odwiedzany jest serwer WWW. Ten obraz jest unikatowy dla danej przeglądarki internetowej i systemu komputerowego. Narysowany obraz jest następnie przekształcany w kod identyfikacyjny, który jest przechowywany na serwerze internetowym na wypadek, gdyby użytkownik odwiedził go ponownie. [9]

|
Obraz - demonstracja odcisków palców |
1. Na pierwszym slajdzie przedstawiono działalność Firefoksa od 30 lipca 2016 r. do 4 sierpnia 2016 r. W tym czasie odwiedzono 154 strony i nawiązano połączenia z 390 witrynami osób trzecich.
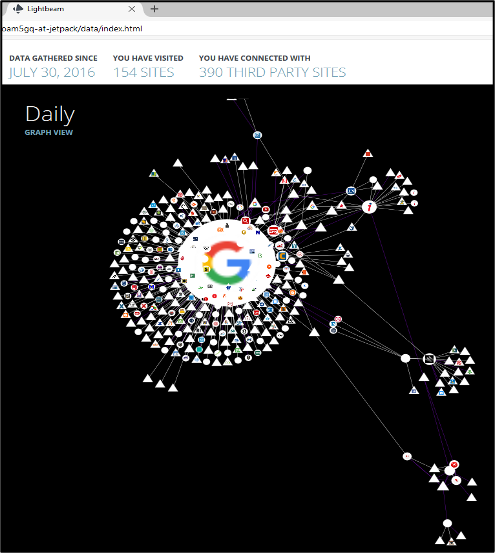
2. Drugi printscreen przedstawia tę samą mapę, ale odfiltrowuje witryny innych firm, które są przedstawione w postaci trójkątów.

3. Ostatni printscreen przedstawia aplikację LightBeam po oczyszczeniu i wyświetleniu następujących stron: www.seznam.cz; www.google.com;

Inne zastosowania
W dalszej części tekstu skupię się częściowo na urządzeniach inteligentnych (smartfonach, tabletach itp.) oraz aplikacjach związanych z faktyczną działalnością "urządzeń inteligentnych". Celowo wybrałem te urządzenia, ponieważ są to systemy komputerowe, na których użytkownicy instalują prawdopodobnie największą liczbę programów (bardzo często niezweryfikowanych, jedynie polecanych przez "znajomego"). To właśnie te urządzenia, które - między innymi ze względu na warunki umowne - mogą nie znajdować się pod pełną kontrolą użytkownika, administratora itp. stanowią zagrożenie bezpieczeństwa zarówno dla użytkownika końcowego, jak i dla firmy (organizacji).
Według wspomnianego wcześniej badania statystycznego[11] , w Internecie spędzamy średnio: 4,4 godziny. (dostęp przez komputer stacjonarny lub laptop itp.) oraz 2,7 godziny (dostęp przez urządzenie mobilne) dziennie. W przypadku komputera bezpieczeństwo urządzenia jest na ogół zapewnione, ale urządzenia przenośne (smartfon, tablet itp.) nie mają zazwyczaj ustalonych zasad dotyczących ewentualnej instalacji oprogramowania (z zaufanych lub niezaufanych źródeł) i często nie mają nawet podstawowej ochrony w postaci oprogramowania antywirusowego.[12]
To przede wszystkim użytkownik końcowy ma możliwość zainstalowania na urządzeniu z systemem Android oprogramowania, które będzie przesyłało (do innych podmiotów) i przechowywało informacje o jego działaniach, w tym przechowywało i przesyłało treść przesyłanych informacji. Usługa Sklep Play udostępniana przez firmę Google w ramach systemu operacyjnego Android pozwala każdemu programiście ustalić zasady dotyczące na przykład tego, co aplikacja ma zbierać i gdzie wysyłać dane.
Osobiście uważam, że nie jest błędem umożliwienie programistom i twórcom aplikacji uzyskania wystarczających informacji o ich aplikacjach, ich funkcjonalności itp. Jeśli uregulujemy gromadzenie tych informacji, to niewątpliwie uregulujemy i utrudnimy ewentualny postęp i dalszy rozwój tych i innych aplikacji. Z drugiej jednak strony istnieją atakujący, którzy - ponieważ Sklep Play nie uwierzytelnia i nie weryfikuje aplikacji - mogą oferować aplikacje zainfekowane złośliwym oprogramowaniem, które po zainstalowaniu w systemie komputerowym użytkownika końcowego mogą na przykład przejąć kontrolę nad jego smartfonem.
Określanie systemu komputerowego na podstawie informacji o jego składnikach
Jednym z unikalnych, ale zmiennych w pewnych okolicznościach, identyfikatorów systemu komputerowego jest adres MAC, który jest ściśle związany z kartą sieciową systemu komputerowego. Karta sieciowa nie jest jednak jedynym elementem sprzętowym, który jest w stanie przesłać niepowtarzalny identyfikator systemu komputerowego do innego systemu komputerowego.
Naukowcy z Uniwersytetu Princeton odkryli, że system komputerowy można zidentyfikować na przykład na podstawie informacji o jego baterii, a przeglądarki internetowe są istotnym elementem przekazywania tych informacji. [13]
W praktyce stosuje się proces, który wykorzystuje możliwości języka HTML5. Standard ten obejmuje funkcję, która pozwala stronie internetowej (lub serwerowi WWW) określić stan baterii systemu komputerowego uzyskującego do niej dostęp (przekazywane są informacje o tym, ile baterii pozostało, jak długo potrwa rozładowanie lub naładowanie). W założeniu właścicieli serwerów WWW użytkownik, którego bateria jest na wyczerpaniu, będzie miał możliwość obejrzenia strony w wersji oszczędzającej energię. Dwa skrypty opisane przez badaczy z Uniwersytetu Princeton wykorzystują już dane dotyczące baterii, zbierając jednocześnie inne informacje - takie jak adres IP czy odciski palców. Takie kombinacje mogą już zapewnić bardzo dokładną identyfikację systemu komputerowego.[14]
8.1.2 Ślad cyfrowy, na który można wpływać
Ślad cyfrowy influencera to wszelkie informacje, które użytkownik dobrowolnie przekazuje innej osobie (fizycznej lub prawnej, a nawet np. dostawcy usług internetowych). Pod pojęciem przekazania należy rozumieć szereg czynności, które mogą polegać np. na wysłaniu wiadomości e-mail, umieszczeniu wpisu w dyskusji, na forum, opublikowaniu dowolnego materiału (zdjęcia, wideo, audio itp.) w sieciach społecznościowych itp. Obejmuje również rejestrację i korzystanie ze wszystkich możliwych usług w cyberprzestrzeni [np. systemów operacyjnych, poczty elektronicznej (w tym bezpłatnej), serwisów społecznościowych, serwisów randkowych, sieci P2P, czatów, blogów, BBS-ów, stron internetowych, usług w chmurze, przechowywania danych itp.]
Ślady cyfrowe, na które można wpływać, to ślady, nad którymi użytkownik może mieć względną kontrolę i to od niego zależy, jakie informacje o sobie zechce udostępnić innym. Należy jednak pamiętać o przedstawionej już przesłance: wszelkie dane lub informacje wprowadzone do cyberprzestrzeni pozostaną w niej.
Teoretycznie można by zdefiniować kategorię śladów hipotetycznie wpływalnych, co jest w pewnym sensie oksymoronem, jednak kategoria ta obejmuje pewne fakty, na które użytkownik teoretycznie może wpływać, tzn. jest w stanie wpływać, ale zazwyczaj tego nie robi, gdyż de facto znacznie ograniczyłoby to możliwości jego funkcjonowania w świecie cyfrowym. Ślady te mogą obejmować np. korzystanie z usług największych dostawców usług internetowych (Microsoft, Apple, Google, Facebook itp.), w przypadku których korzystanie z usług jest uzależnione od uzgodnienia warunków umownych (EULA), które pozwalają tym dostawcom uzyskać znaczną ilość informacji. Ponadto ślady te mogą obejmować ślady utworzone na przykład w wyniku korelacji śladów nieinfluencyjnych i wpływowych; informacje publikowane na nasz temat przez innych użytkowników; dane, które są odzwierciedlane; dane EXIF[15]
[1] Lub, w większości, informacje, które są rejestrowane i archiwizowane na temat aktywności użytkownika w miejscach, do których użytkownik nie ma dostępu i nad którymi nie ma kontroli [np. użytkownik nie jest w stanie usunąć dzienników pokazujących jego aktywność (np. uzyskiwanie dostępu, wysyłanie wiadomości e-mail itp.) na serwerze pocztowym]. Na własnym komputerze użytkownik może wpływać na przechowywane dane i informacje. Ma on prawo do usuwania (np. historii, e-maili itp.), edytowania itp.
[2] Regionalne rejestry internetowe. Dostępne pod adresem: https://www.nro.net/about-the-nro/regional-internet-registries
[3] Jest to osoba kontaktowa, do której użytkownik może się zwrócić w przypadku wyrządzenia mu szkody przez dany adres IP lub zakres adresów (np. cyberatak w postaci spamu, phishingu itp.). Jest to kontakt znajdujący się najbliżej źródła ataku.
[4] Nie są to jednak jedyne bazy danych. Istnieje wiele serwisów, które oferują te same informacje. Na przykład istnieją inne bazy danych: http://whois.domaintools.com/; https://www.whois.net/; http://www.nic.cz/whois/; https://whois.smartweb.cz/ itd.
[5] wiadomość e-mail została przekazana z adresu: jan.kolouch@fit.cvut.cz na adres e-mail: kyber.test@seznam.cz
[6] W protokole HTTP plik cookie oznacza niewielką ilość danych, która jest wysyłana przez odwiedzający serwer WWW (prościej: odwiedzaną stronę WWW) do przeglądarki internetowej, która następnie zapisuje ją na komputerze użytkownika. Dane te są następnie przesyłane z powrotem do serwera WWW za każdym razem, gdy odwiedzany jest ten sam serwer.
[7] Jeśli użytkownik chce dowiedzieć się więcej o tym, co przeglądarka internetowa ujawnia na temat jego aktywności, polecam następujące adresy URL: http://panopticlick.eff.org , http://browserspy.dk/, http://samy.pl/evercookie.
[8] ANGWIN, Julia. Poznaj urządzenie śledzące online, które jest praktycznie niemożliwe do zablokowania. Dostępne pod adresem: https://www.propublica.org/article/meet-the-online-tracking-device-that-is-virtually-impossible-to-block
[9] Pokaz pobierania odcisków palców w Canavas. Możesz wypróbować test pokazujący odcisk palca przeglądarki w artykule ANGWIN, Julia. Poznaj urządzenie śledzące online, które jest praktycznie niemożliwe do zablokowania. Dostępne pod adresem: https://www.propublica.org/article/meet-the-online-tracking-device-that-is-virtually-impossible-to-block
[10] Aplikacja umożliwia graficzne przedstawienie powiązań między poszczególnymi usługami oraz przekazywanie informacji stronom trzecim. Jest to dodatek do przeglądarki internetowej Firefox, dostępny pod adresem: https://www.mozilla.org/en-US/lightbeam/.
[11] Digital, Social & Mobile Worldwide in 2015 [online]. Dostępne pod adresem: http://www.slideshare.net/wearesocialsg/digital-social-mobile-in-2015?ref=http://wearesocial.net/blog/2015/01/digital-social-mobile-worldwide-2015/
[12] Należy zauważyć, że na przykład z raportu opublikowanego przez Kaspersky Lab wynika, że istnieje ponad 340 000 typów szkodliwego oprogramowania przeznaczonego głównie dla urządzeń mobilnych. Kaspersky Lab twierdzi ponadto, że 99% tego szkodliwego oprogramowania jest kierowane na urządzenia z systemem Android. Należy zauważyć, że takie ukierunkowanie jest całkowicie zrozumiałe, ponieważ zróżnicowanie urządzeń i wersji systemu operacyjnego Android jest znaczne (niektóre raporty podają, że system operacyjny Android jest wykorzystywany przez ponad 24 000 różnych urządzeń).
Więcej informacji na ten temat można znaleźć np:
Pierwsze mobilne szkodliwe oprogramowanie: jak Kaspersky Lab odkrył Cabir. [online]. Dostępne pod adresem: http://www.kaspersky.com/about/news/virus/2014/The-very-first-mobile-malware-how-Kaspersky-Lab-discovered-Cabir
Wejdź na stronę: Ciekawe statystyki dotyczące mobilnych strategii transformacji cyfrowej [online]. Dostępne pod adresem: http://www.smacnews.com/digital/interesting-statistics-on-mobile-strategies-for-digital-transformations/
Fragmentacja systemu Android bije kolejne rekordy: 24 000 różnych urządzeń [online]. Dostępne pod adresem: http://appleapple.top/the-fragmentation-of-android-has-new-records-24-000-different-devices/
[13] Więcej informacji można znaleźć w materiałach ENGLEHARDT, Steven i Ardvin NARAYANAN. Śledzenie w Internecie: Pomiar i analiza 1 miliona miejsc. [online]. Dostępne pod adresem: http://randomwalker.info/publications/OpenWPM_1_million_site_tracking_measurement.pdf
[14] Więcej informacji na ten temat można znaleźć w artykule VOŽENÍLEK, David. Nie pomoże smarowanie "sucharów", internet cię wyda i baterie. [online]. Dostępne pod adresem: http://mobil.idnes.cz/sledovani-telefonu-na-internetu-stav-baterie-faz-/mob_tech.aspx?c=A160802_142126_sw_internet_dvz
[15] EXIF - wymienny format plików graficznych. Jest to format metadanych umieszczanych w zdjęciach cyfrowych przez aparaty cyfrowe. Metadane te może na przykład być:
- Marka i model aparatu.
- Data i godzina wykonania zdjęcia.
- Pozycja GPS.
- Informacje o autorze (osobie, która zarejestrowała aparat).
- Ustawienia aparatu.
- Podgląd obrazu.